 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Do Patients Say About Their Disease Symptoms? Deep Multilabel Text Classification With Human-in-the-Loop Curation for Automatic Labeling of Patient Self Reports of Problems
May 08, 2023



The USA Food and Drug Administration has accorded increasing importance to patient-reported problems in clinical and research settings. In this paper, we explore one of the largest online datasets comprising 170,141 open-ended self-reported responses (called "verbatims") from patients with Parkinson's (PwPs) to questions about what bothers them about their Parkinson's Disease and how it affects their daily functioning, also known as the Parkinson's Disease Patient Report of Problems. Classifying such verbatims into multiple clinically relevant symptom categories is an important problem and requires multiple steps - expert curation, a multi-label text classification (MLTC) approach and large amounts of labelled training data. Further, human annotation of such large datasets is tedious and expensive. We present a novel solution to this problem where we build a baseline dataset using 2,341 (of the 170,141) verbatims annotated by nine curators including clinical experts and PwPs. We develop a rules based linguistic-dictionary using NLP techniques and graph database-based expert phrase-query system to scale the annotation to the remaining cohort generating the machine annotated dataset, and finally build a Keras-Tensorflow based MLTC model for both datasets. The machine annotated model significantly outperforms the baseline model with a F1-score of 95% across 65 symptom categories on a held-out test set.
Investigating the Utility of Multimodal Conversational Technology and Audiovisual Analytic Measures for the Assessment and Monitoring of Amyotrophic Lateral Sclerosis at Scale
Apr 15, 2021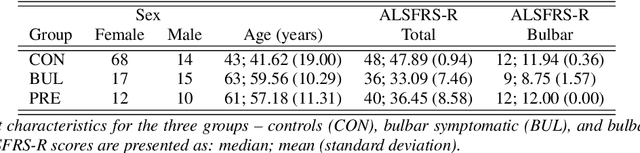
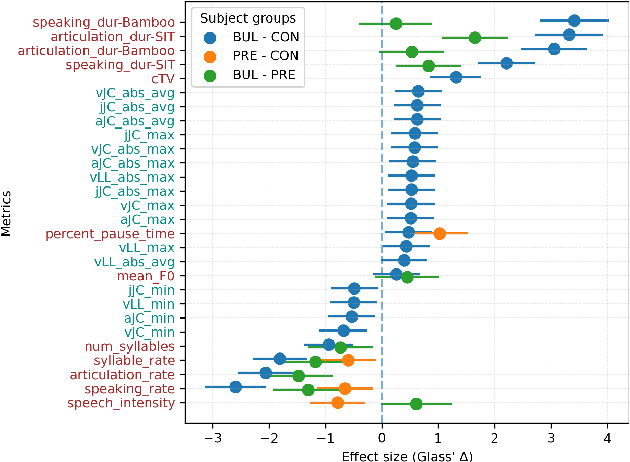

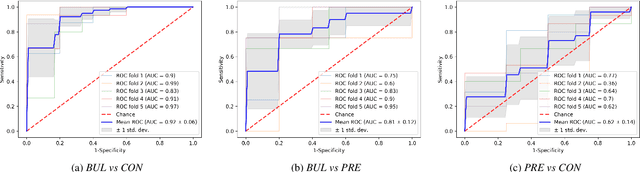
We propose a cloud-based multimodal dialog platform for the remote assessment and monitoring of Amyotrophic Lateral Sclerosis (ALS) at scale. This paper presents our vision, technology setup, and an initial investigation of the efficacy of the various acoustic and visual speech metrics automatically extracted by the platform. 82 healthy controls and 54 people with ALS (pALS) were instructed to interact with the platform and completed a battery of speaking tasks designed to probe the acoustic, articulatory, phonatory, and respiratory aspects of their speech. We find that multiple acoustic (rate, duration, voicing) and visual (higher order statistics of the jaw and lip) speech metrics show statistically significant differences between controls, bulbar symptomatic and bulbar pre-symptomatic patients. We report on the sensitivity and specificity of these metrics using five-fold cross-validation. We further conducted a LASSO-LARS regression analysis to uncover the relative contributions of various acoustic and visual features in predicting the severity of patients' ALS (as measured by their self-reported ALSFRS-R scores). Our results provide encouraging evidence of the utility of automatically extracted audiovisual analytics for scalable remote patient assessment and monitoring in ALS.
Exploring Recurrent, Memory and Attention Based Architectures for Scoring Interactional Aspects of Human-Machine Text Dialog
May 20, 2020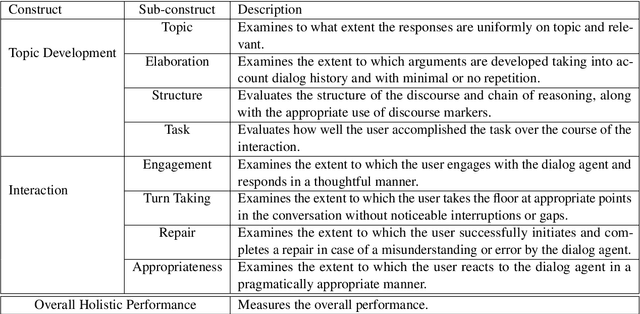
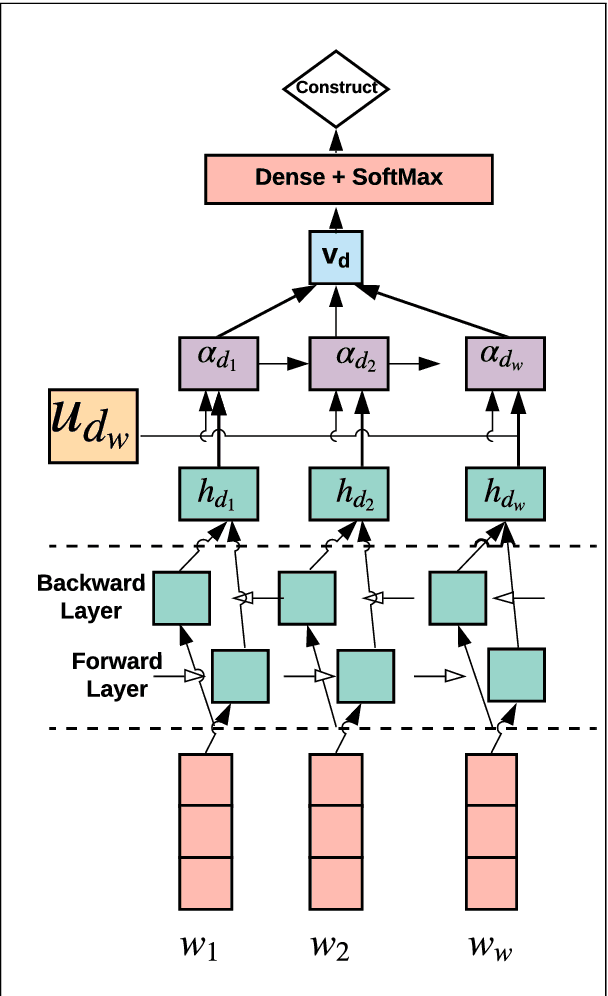
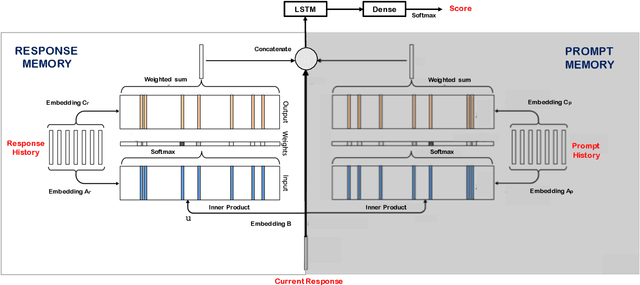
An important step towards enabling English language learners to improve their conversational speaking proficiency involves automated scoring of multiple aspects of interactional competence and subsequent targeted feedback. This paper builds on previous work in this direction to investigate multiple neural architectures -- recurrent, attention and memory based -- along with feature-engineered models for the automated scoring of interactional and topic development aspects of text dialog data. We conducted experiments on a conversational database of text dialogs from human learners interacting with a cloud-based dialog system, which were triple-scored along multiple dimensions of conversational proficiency. We find that fusion of multiple architectures performs competently on our automated scoring task relative to expert inter-rater agreements, with (i) hand-engineered features passed to a support vector learner and (ii) transformer-based architectures contributing most prominently to the fusion.
To Trust, or Not to Trust? A Study of Human Bias in Automated Video Interview Assessments
Nov 27, 2019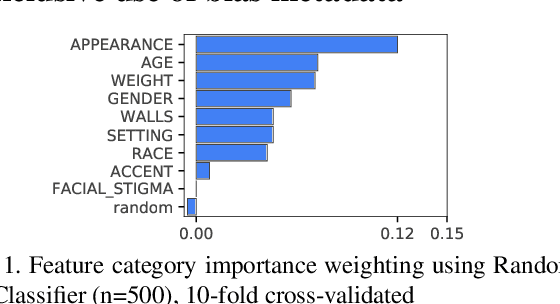
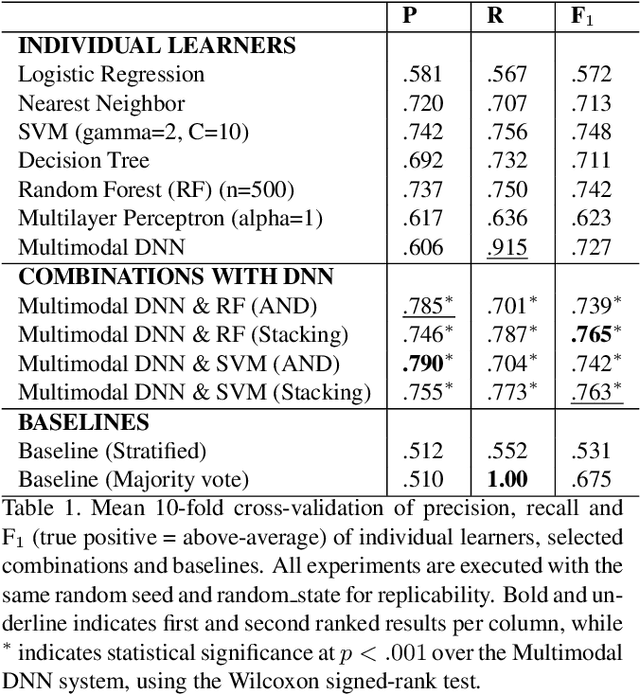
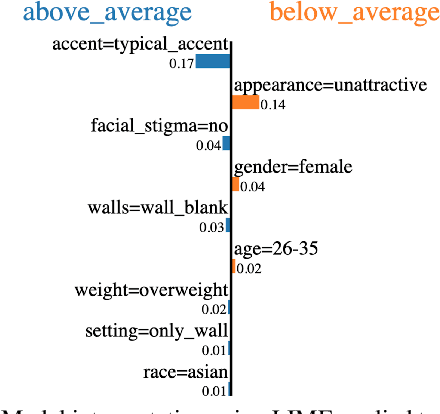
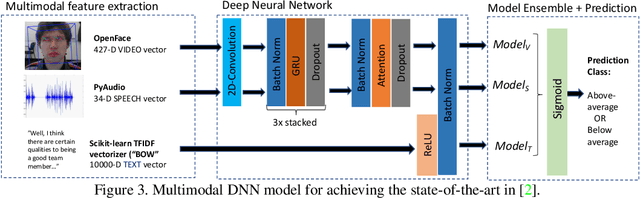
Supervised systems require human labels for training. But, are humans themselves always impartial during the annotation process? We examine this question in the context of automated assessment of human behavioral tasks. Specifically, we investigate whether human ratings themselves can be trusted at their face value when scoring video-based structured interviews, and whether such ratings can impact machine learning models that use them as training data. We present preliminary empirical evidence that indicates there might be biases in such annotations, most of which are visual in nature.